こんにちは、小船井です。
秋がなかなかやって来ませんね。秋になると弊社ビルの駐車場にある金木犀の香りが3階オフィスまでほんのり香ってくるのですが、もう少し先のようです。
みなさま、日中の暑さにはまだまだお気をつけてお過ごしください。
今回の投稿では、日々お客様からご相談を受ける中でよく質問を受けることに対して書いてみようと思います。
「画像は何枚あれば検査できるの?」
→これに対しての答えは「(正確には)わかりません」です。
仮に、認識させたい対象物をAとすると、画像内の重要な特徴の抽出が “対象物A” としてAIに正しく認識されるゴールまでには、、、
- どれだけの学習データを与えればいいのか
- 何回学習データを作り直す作業が必要なのか
以上のことが実際に学習データを作りを行い、処理(検査して行ってみる)までは分からないからです。
そのため、重要な特徴が「黒くて丸い」だけでAとして認識されるなら少ない画像で済むし、「黒かったりグレーだったり色が変わるし、丸だったり楕円だったりする形で、大きさも変わるし、カメラに映る時に角度も変わる」といった特徴項目が多い場合には、「黒くて丸い」よりも多くの画像が必要となることが多いです。
なので、実際に検証を行う時のシンプルな流れとしてはこのようになります。(例として画像は200枚で説明しています)
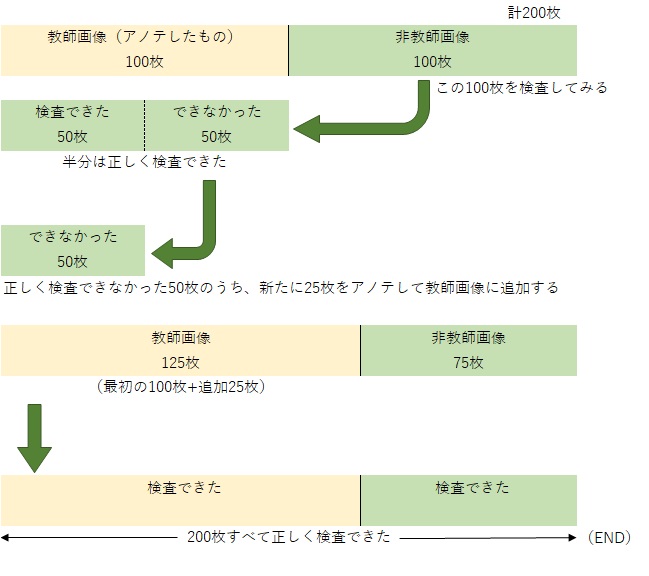
- 実際に検査をさせたい製品を撮った200枚前後の画像を用意する。
※画像データ水増しで1つの画像から増やして画像を用意してもOK - その200枚のうち、100枚の画像に対して、対象物Aに対してアノテーション(囲ったものはAですよ と【A】という名前をつけてAIに教えるための作業)を行う。
- アノテーションした画像をもとに学習データを作り、②で使用した200枚のうちの残りの100枚 を使って処理(検査してみる)を行い、正しくAと認識したのかをチェックする。
- ひととおり画像を検査してみて、全て正しく検査できていれば成功(END)
上記、2~4ではAIにとってはこんな状態です。
★画像内の特徴を抽出
(ふむふむ、Aはこういった特徴をもつのかー)
↓
★画像内のどの部分が物体に対応するかを判断
(この画像の中でさっきの特徴をもつのはこのあたりだな!なんかAっぽいぞ)
↓
★検出された物体がなにであるかを学習データと照らし合わせて識別
(よし、さっきの学習データを基にこいつがちゃんとAなのか見極めてみよう!)
真面目に作業を文字に起こすと、当たり前なことをして、さらに面倒な作業だなと思ってしまいますが、スタート時点ではまだなにも知らないゼロからの状態のAIにはきちんと教えてあげないと正しく認識してくれないのです。とってもピュアな赤ちゃん状態です。
AじゃないものをAと認識してしまったり、AなのにAと認識しなかったら「もう1回学習データを作り直そう(RETRY)」となります。この①~④までの作業を、使用する画像を少しずつ(50枚ずつとか)増やして、アノテーションを追加して学習データを増やしながら、納得いく結果がでるENDとなるまで繰り返し検証していくのです。
そのため、この1~4までの作業が1回で済むこともあるし、3回、5回、10回必要になる場合も。
RETRYの場合、アノテする画像(教師画像)も検査させる非教師画像も最初より多く必要になるため、スタートの200枚から必要な画像は増えていくことになります。
以上、長くなってしまいましたが、「画像は何枚あれば検査できるの?」に対して書いてみました。ご拝読いただきありがとうございました。