

新機能:OCR Proの「強制変換」機能について
こんにちは。なつめです。
例年ですと、今はたけのこの季節になりますが、
今年はたけのこがあまり取れないそうです。
昨年の台風による塩害が原因だとか…。
毎年楽しみにしているたけのこ料理が味わえず、少し口さみしい春です。
さて、今回はOCR Proの読取強化にお応えする新機能「強制変換」機能についてご紹介します。
OCR読取時、文字列に英字と数字が混合していますと、
0(ゼロ)をO(オー)と読んでしまったり、8(ハチ)をB(ビー)と誤読取りしてしまうことが多くあります。
今回の「強制変換」機能では、3番目の文字は英字とか5番目の文字は数字といったように指定ができるようになりました。
例えば、「2370 LBS」という文字列を読取るとします。
そのまま読取りを行いますと、読取り結果は「2370 L8S」になりました。
B(ビー)を8(ハチ)と誤読取りしています。
(0(ゼロ)をO(オー)と誤読取りする可能性も考えられます。)
例年ですと、今はたけのこの季節になりますが、
今年はたけのこがあまり取れないそうです。
昨年の台風による塩害が原因だとか…。
毎年楽しみにしているたけのこ料理が味わえず、少し口さみしい春です。
さて、今回はOCR Proの読取強化にお応えする新機能「強制変換」機能についてご紹介します。
OCR読取時、文字列に英字と数字が混合していますと、
0(ゼロ)をO(オー)と読んでしまったり、8(ハチ)をB(ビー)と誤読取りしてしまうことが多くあります。
今回の「強制変換」機能では、3番目の文字は英字とか5番目の文字は数字といったように指定ができるようになりました。
例えば、「2370 LBS」という文字列を読取るとします。
そのまま読取りを行いますと、読取り結果は「2370 L8S」になりました。
B(ビー)を8(ハチ)と誤読取りしています。
(0(ゼロ)をO(オー)と誤読取りする可能性も考えられます。)

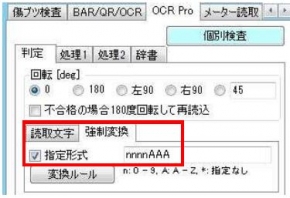
そこで、新機能「強制変換」機能を使用します。
「指定形式」に文字列の内容を入力します。
数字はn、英字はAと打ち込みます。
今回の「2370 LBS」は、「nnnnAAA」になります。
「指定形式」に文字列の内容を入力します。
数字はn、英字はAと打ち込みます。
今回の「2370 LBS」は、「nnnnAAA」になります。
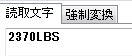
正しく読み取ることができました。
ぜひ、ご活用いただけますと幸いです。
ご不明点等ございましたら、
お気軽にお問い合わせくださいませ。
(2019.4.17)
ぜひ、ご活用いただけますと幸いです。
ご不明点等ございましたら、
お気軽にお問い合わせくださいませ。
(2019.4.17)